Record the Evidences: Build Goodreads Best Crime and Mystery Books Dataset
06 March 2023
Background and Motivation
In today’s job market, I fully understand the importance of having a solid portfolio to stand out from the crowd and get noticed by potential employers. However, building one can be challenging, especially if we need help knowing where to start. Luckily, our incredible friend Google Search can help. By typing “data analyst project” on the search bar, I got the responses like those in the image below.
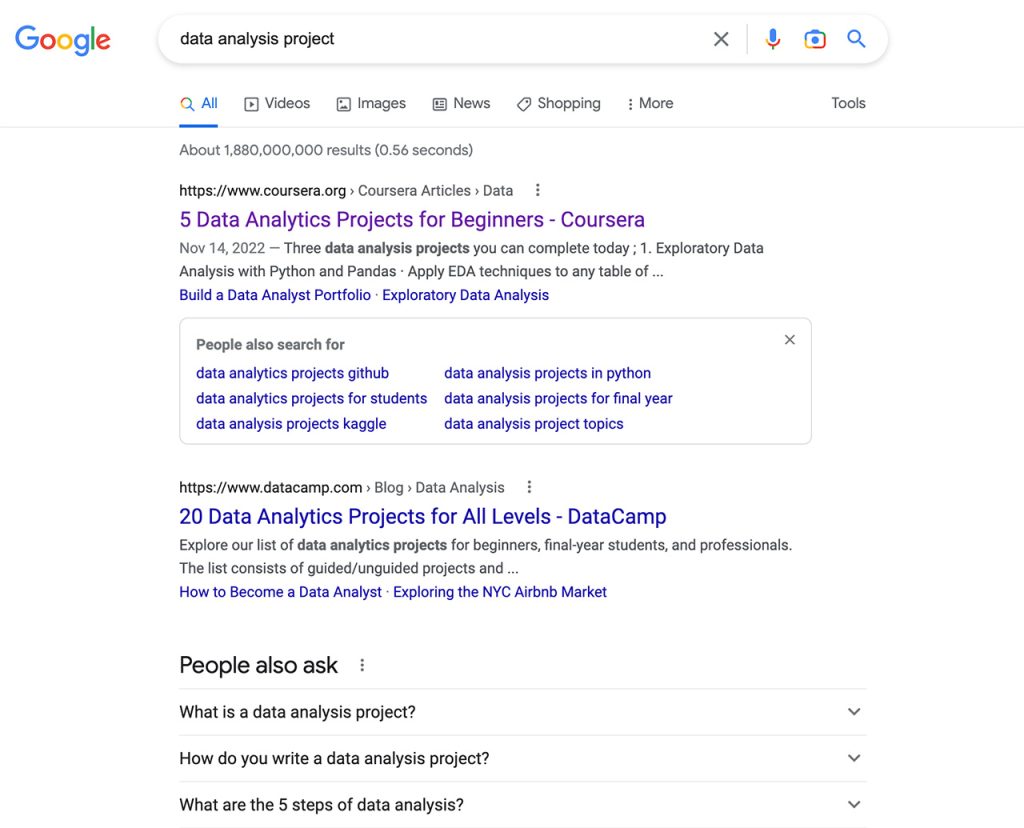
I chose an article from the topmost answer and followed their suggestion by starting the first project on the list: web scraping.
The article suggested Beautiful Soup or Scrapy library to crawl the web. I chose Beautiful Soup because they mentioned it first; I did not explore the crawler libraries.
Data scraping involves extracting data from websites and saving it in a structured format. Since I love crime and mystery books, I selected the best crime and mystery books list on Goodreads as my source. And later, I saved the data in CSV format; hence we can utilize it for a future project. In short, three working blocks in this project are:
- saving website pages into documents,
- scraping data from the documents, and
- saving the data into a CSV file.
Project Blocks
STEP 1: Save website pages into documents
The pages I work with were Goodreads’ best crimes and mystery books. They consist of 69 pages. With help from the requests library, I opened and retrieved all pages’ content. Then, I saved each page’s content into a different HTML document.
I built two pages for this step: (1) html_docs.py to host the HTMLDocs class that gets the website page, retrieves its content, and saves the content in a document, and (2) main.py that calls HTMLDocs class and iterates savedoc() function from that class for all pages we want to read.
html_docs.py
import requests
class HTMLDocs:
def __init__(self, main_url, my_title, queryable_object):
self.main_url = main_url
self.title = my_title
self.queryable_object = queryable_object
self.text = ""
def get_doc(self, page_number):
url = self.main_url
if page_number > 1:
url += f"{self.queryable_object}{page_number}"
page = requests.get(url)
self.text = page.text
def save_doc(self, page_number):
self.get_doc(page_number)
with open(f"{self.title}_{page_number}.html", "w") as doc:
doc.write(self.text)main.py
from html_docs import HTMLDocs
TITLE = "goodreads_crime_mystery_books" # title for documents
URL = "https://www.goodreads.com/list/show/11.Best_Crime_Mystery_Books"
QUERYABLE_OBJECT = "?page=" # query string
MAX_PAGE = 69 # maximum number of pages
html_doc = HTMLDocs(URL, TITLE, QUERYABLE_OBJECT)
for i in range(1, MAX_PAGE+1): # iterate from first page to the last page
html_doc.save_doc(i)STEP 2: Scrap data from documents
The data we can scrap from the crime and mystery books list are title, author, average rating, number of ratings, score, and number of voters. For example, for the first rank book, the title is The Girl with the Dragon Tattoo (Millennium, #1), the author is Stieg Larsson, the average rating is 4.16, the number of ratings is 3,012,134, the score is 306,573, and the number of voters is 3,099.
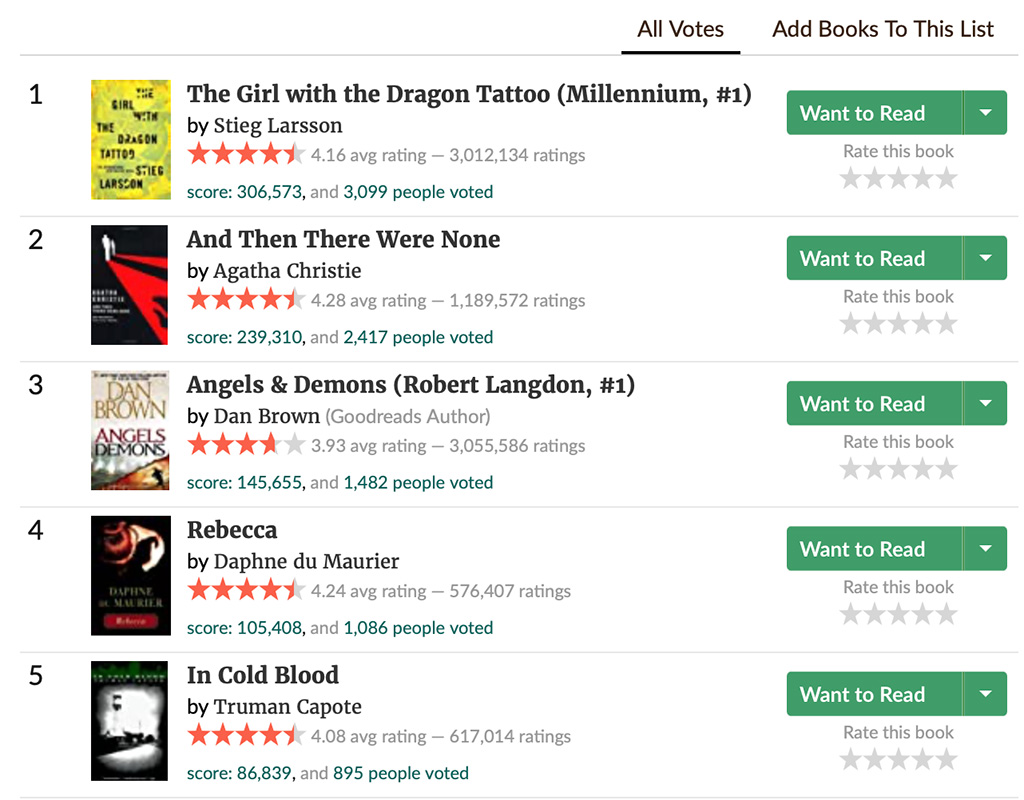
The beautiful soup (bs4) library takes action in this second step. I used the find_all() method to search the parse tree. Beautiful Soup filters the class attribute to locate the title, author, rating, and number of ratings, (b) the text string pattern to find the score, and (c) both the id attribute and id name pattern to see the number of voters.
soup.find_all(tag, attribute)
soup.find_all(string=re.compile(pattern))
soup.find_all(attribute=re.compile(pattern))# After executing the find_all() method, the five first items in the scores list from the first page are below.
print(scores[:5])
Next, for each location found, I extracted the data by using the text() method. Notice, before locating the exact position of the correct data, I have to split the list items that have more than one word, e.g., average rating, the number of ratings, the score, and the number of voters.
For example, each item in scores has two words: “score:” and “{number}”. After splitting an item in the scores list, we must locate the last index item to get the correct number.
So I could convert a number from string to integer, I also had to remove the thousands separator (“,”).
"score": int(scores[j].text.strip().split()[-1].replace(',', ''))I concluded this step by storing all the extracted data in a dictionary.
from bs4 import BeautifulSoup
books_dict = []
for i in range(1, MAX_PAGE+1):
# Open the html document
with open(f"{TITLE}_{i}.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
# Locate the data we want to extract from the document
rank = soup.find_all("td", {"class": "number"})
title_tags = soup.find_all("a", {"class": "bookTitle"})
author_names = soup.find_all("a", {"class": "authorName"})
ratings = soup.find_all("span", {"class": "minirating"})
n_ratings = soup.find_all("span", {"class": "minirating"})
scores = soup.find_all(string=re.compile("score:"))
n_voters = soup.find_all(id=re.compile("loading_link_"))
# Extract the data
for j in range(len(title_tags)):
book_item = {
"rank": int(rank[j].text.strip()),
"title": title_tags[j].text.strip(),
"author": author_names[j].text.strip(),
"avg_rating": float(ratings[j].text.strip().split()[-6]),
"n_rating": int(ratings[j].text.strip().split()[-2].replace(',', '')),
"score": int(scores[j].text.strip().split()[-1].replace(',', '')),
"n_voter": int(n_voters[j].text.strip().split()[0].replace(',', ''))
}
books_dict.append(book_item)Notes
The data is missing 100 entries from page 27. After several attempts, the program could only open “Goodreads request took too long” page that contain no information I was trying to locate.
print(soup.prettify())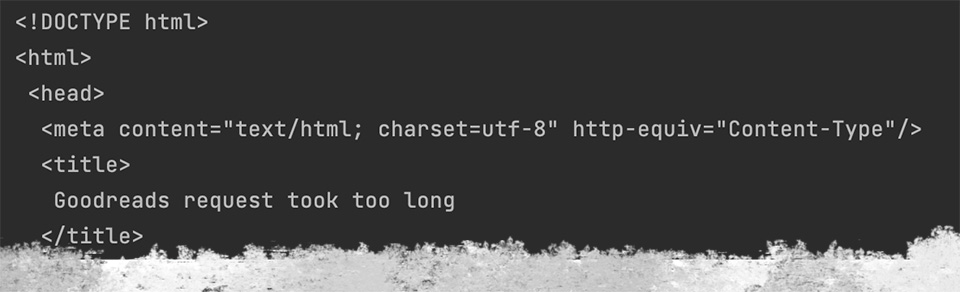
STEP 3: Save the data into a CSV file
Using pandas library, I turned the dictionary into a data frame. Last, I converted that data frame into a CSV file.
import pandas as pd
books_df = pd.DataFrame(books_dict)
books_df.to_csv(f"{TITLE}.csv", index=False)Complete Code and CSV File
I collected 6,767 rows of data from 69 pages of Goodreads’ Best Crime and Mystery Books list. CSV file – last updated March 3, 2022
I am glad I found an article that inspired me to start this project and the resources that helped me along the way. Not only did I learn a valuable skill, but I also had a tangible project to showcase in my portfolio.
P.S. Here is my recommended crime and mystery reads.*
*As an Amazon Associate, I earn from qualifying purchases.